A Isca do True Crime: Como uma regra do Scribd expôs conversas privadas de WhatsApp de milhares de brasileiros
O Vazamento
Um erro silencioso de design pode estar fazendo suas conversas do WhatsApp aparecerem nos resultados de pesquisa do Google. Centenas de documentos contendo mensagens íntimas, brigas de família, flertes e dados sensíveis de cidadãos brasileiros estão indexados e acessíveis publicamente no maior buscador do mundo.
Não estamos falando de um ataque hacker nem de um vírus sofisticado. Este vazamento está acontecendo à luz do dia, e as conversas estão armazenadas em uma das plataformas de leitura mais famosas da internet: o Scribd. Tudo disponível para qualquer pessoa ler, gratuitamente.
Nota metodológica: Para dimensionar o problema, utilizamos dois operadores de busca distintos no Google. O operador
allintitle: "Conversa Do WhatsApp Com" site:scribd.comretorna páginas cujo próprio título contém o cabeçalho padrão gerado pelo WhatsApp ao exportar uma conversa — são os casos mais inequívocos. No momento da publicação deste artigo, essa busca retorna 108 resultados. Dois dias antes de publicarmos, retornava 450. A busca mais ampla"Conversa Do WhatsApp Com" site:scribd.com, que inclui menções ao termo em qualquer parte do documento, retorna cerca de 7.000 resultados.
Alguns usuários já notaram o problema por conta própria. No Reclame Aqui, multiplicam-se relatos de brasileiros que digitaram seus próprios nomes e encontraram planilhas com telefones e endereços, ou logs inteiros de conversas expostos publicamente. Em outubro de 2025, um usuário comunicou à empresa:
"Ao pesquisar o nome de uma amiga, encontrei documentos pessoais com todos os dados expostos nesse site, sem ocultar número de documentos importantes."
Embora o problema tenha chamado nossa atenção inicialmente através de buscas em português, o vazamento pode alcançar proporções internacionais. Ao buscar pelas traduções equivalentes do arquivo de .txt gerado ao exportar uma conversa, encontramos milhares de resultados em inglês ("WhatsApp Chat with"), espanhol ("Chat de WhatsApp con") e francês ("Discussion WhatsApp avec").
Em 2013, o Scribd havia sofrido um ataque hacker que resultou no vazamento de cerca de 1 milhão de senhas. Este não parece ser o caso agora. O que encontramos é diferente — e de certa forma mais preocupante: não há invasor externo. O mecanismo é a própria plataforma.
A Anatomia do Vazamento: A "Moeda de Troca" do Scribd
Quid Pro Quo: Upload por Download
Para entender a magnitude desta falha de privacidade, é preciso primeiro compreender a mecânica de acesso que a originou. O Scribd, conhecido como a "Netflix dos PDFs e livros", opera sob um modelo de assinatura paga. No entanto, a plataforma oferece uma rota de contorno para usuários gratuitos: o sistema de "upload por download". Se você deseja baixar um documento sem ser assinante, a plataforma exige um "pedágio digital" — você envia um arquivo seu para poder baixar outro.
[Tela do Scribd exibindo a mensagem "Faça o upload de 3 documentos para fazer um download", com o título de um documento true crime visível ao fundo.]
É exatamente nessa fricção de interface que o desastre ocorre.
O Ponto de Fricção
Diante da barreira de pagamento e da urgência em acessar um conteúdo, o usuário leigo procura o arquivo mais rápido e acessível que possui em seu smartphone. A resposta está a poucos toques de distância no aplicativo mais popular do país. O recurso nativo do WhatsApp, "Exportar Conversa", permite compilar anos de mensagens em um arquivo .txt leve e instantâneo.
Desesperado pela "moeda de troca" exigida pelo Scribd, o usuário faz o upload desse arquivo de texto. A crença é a de que ele servirá apenas como uma validação burocrática e cega do sistema. O que ele não percebe é que o Scribd cataloga, hospeda e publica esse documento em seu site, tornando-o acessível a qualquer pessoa — e indexável pelo Google.
Um Fenômeno de Engenharia Social Acidental
A prova de que estamos diante de um fenômeno de engenharia social acidental — e não de uma raspagem maliciosa por hackers — está nos próprios metadados dos vazamentos. Em nossa apuração, os nomes dos perfis que realizaram o upload dos arquivos no Scribd coincidem quase sempre com um dos nomes registrados no cabeçalho das conversas vazadas. São os próprios titulares dos dados entregando sua intimidade como pagamento de um pedágio invisível.
O que os Documentos Expostos Contêm
[Print censurado e anonimizado de uma das conversas encontradas no Scribd.]

Os documentos expostos variam em grau de sensibilidade. Em nossa apuração, encontramos conversas que contêm:
- Números de telefone completos, incluindo DDI +55 (Brasil), +1 (Estados Unidos) e +33 (França), expostos nos próprios títulos dos documentos
- Nomes completos de ambos os participantes da conversa
- Discussões sobre gravidez, dívidas, relacionamentos e saúde
- Dados de atendimento bancário, incluindo perguntas de segurança respondidas pelo usuário
- Endereços de email
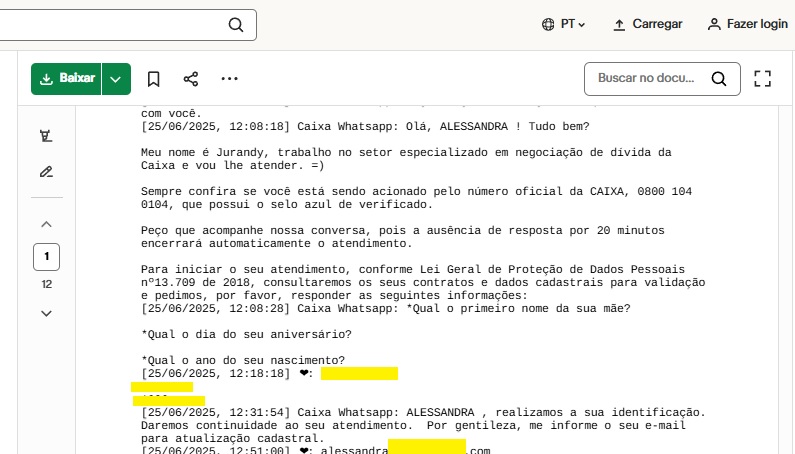
Um dos casos mais graves que identificamos continha um log de atendimento de um suposto canal de suporte do Caixa Econômica Federal via WhatsApp, no qual o usuário fornecia respostas a perguntas de segurança como nome da mãe, data de aniversário e ano de nascimento.
[Print censurado e anonimizado do que parece ser uma conversa com um canal legítimo da Caixa Econômica Federal.]
O Sistema do Scribd Sabia
O detalhe mais revelador de toda esta apuração está em uma funcionalidade aparentemente trivial da plataforma: o painel de "Dados do documento". Ao abrirmos um dos arquivos expostos diretamente no Scribd, o sistema exibe automaticamente um resumo gerado por inteligência artificial descrevendo o conteúdo — incluindo, no caso que documentamos: "estado de gravidez de uma conhecida, a morte de outra conhecida, e o relacionamento de várias outras pessoas."
[Print do painel "Dados do documento" do Scribd"]
Em outras palavras: o sistema de IA do Scribd leu o documento, identificou seu conteúdo sensível, o classificou com direitos autorais reservados — e ainda assim o manteve publicado e disponível para download. A plataforma reconheceu o problema e não o resolveu automaticamente.
A Escala Global: Um Problema Muito Além do Brasil
Embora o problema tenha chamado nossa atenção por buscas em português, a falha não possui fronteiras. O padrão de exportação do WhatsApp muda de acordo com o idioma do sistema operacional do usuário, o que significa que o mesmo fenômeno ocorre em outros idiomas.
Utilizando os termos equivalentes ao cabeçalho de exportação do WhatsApp em cada língua, identificamos:
- Inglês (
"WhatsApp Chat with" site:scribd.com): aproximadamente 35.000 resultados - Espanhol (
"Chat de WhatsApp con" site:scribd.com): aproximadamente 20.000 resultados - Francês (
"Discussion WhatsApp avec" site:scribd.com): milhares de resultados adicionais
Importante: Buscas simples no Google retornam estimativas que podem incluir falsos positivos — páginas que mencionam o termo sem conter necessariamente um log de conversa. Os números acima representam a busca ampla. Os resultados do operador
allintitle:, que isola apenas documentos cujo título é o cabeçalho de exportação do WhatsApp, são mais conservadores e confiáveis como medida de casos inequívocos.
Mesmo com essa ressalva, o volume de documentos potencialmente expostos globalmente aponta para dezenas de milhares de arquivos com dados pessoais identificáveis, distribuídos por múltiplos idiomas e regiões. O que parecia ser uma questão regional revela-se um incidente de escala internacional.
O Efeito Matsunaga e Richthofen
Se a mecânica do vazamento é um defeito de design, o que está levando milhares de brasileiros a caírem nessa armadilha simultaneamente? A resposta está nos dados de comportamento de busca.
[Gráfico do Google Trends mostrando o crescimento nas buscas por "scribd" entre março de 2021 e março de 2026.]
Ao cruzarmos os dados do Google Trends com o histórico dos vazamentos, uma tempestade perfeita se desenha. O crescimento nas buscas por "Scribd" no Brasil não é impulsionado por interesse em literatura acadêmica — é impulsionado pelo true crime brasileiro.
Termos como "scribd marcos matsunaga" e "baixar do scribd" aparecem consistentemente entre os principais termos relacionados à plataforma no Google.
[Print da tela de "Pesquisas relacionadas" do Google Trends mostrando alguns dos principais termos.]
Quando documentários, podcasts ou séries sobre crimes de repercussão nacional ganham popularidade, uma massa de usuários corre para a internet em busca de laudos periciais, sentenças ou livros que frequentemente estão hospedados no Scribd. O pico mais recente e documentado coincide com o lançamento do seriado "Tremembé" no streaming.
[Gráfico comparativo mostrando o pico de buscas por "scribd" poucos dias após o lançamento do seriado "Tremembé".]
Atraído pelo interesse nos casos de true crime, o usuário esbarra na parede de pagamento. Procurando atalhos, é induzido ao sistema de upload. A curiosidade por um crime famoso tornou-se a isca para que milhares de cidadãos expusessem, de forma permanente, suas próprias vidas privadas.
O que Google, Meta e Scribd Responderam
Em 16 de março de 2026, notificamos formalmente o Google, a Meta (WhatsApp) e o Scribd sobre o problema, informando nossa intenção de publicar e solicitando posicionamento oficial até as 14h do dia 18 de março (horário de Brasília). As respostas revelam níveis distintos de compreensão sobre o problema.
A assessoria de imprensa do Google no Brasil respondeu pedindo evidências do ocorrido. Fornecemos os operadores de busca e prints anonimizados, evitando deliberadamente enviar links diretos para não atuar como vetor de exposição de dados de terceiros. A assessora confirmou o recebimento e informou que retornaria "assim que tiver retorno". Até o fechamento desta edição, não houve posicionamento oficial do Google.
Meta / WhatsApp
A assessoria da Meta entrou em contato pedindo mais contexto e demonstrou, em suas mensagens, não estar familiarizada com a dinâmica do vazamento — o que sugere que a empresa não tinha conhecimento prévio do problema. Fornecemos a mesma documentação enviada ao Google. Até o fechamento desta edição, a Meta também não emitiu posicionamento oficial.
Vale registrar que a responsabilidade da Meta neste caso é mais limitada: o recurso "Exportar Conversa" do WhatsApp funciona exatamente como previsto. O problema não está no aplicativo, mas no uso que o Scribd faz dos arquivos enviados e na ausência de filtros adequados.
Scribd
O Scribd foi a única das três empresas a emitir uma resposta com conteúdo substantivo. Em inglês, a empresa afirmou:
"Scribd strictly prohibits the unauthorized posting of personal information. [...] we leverage a mix of human and automated tools. We are constantly evolving these systems [...]. While our members are free to post their own personal information at their discretion, we take reports of unauthorized exposure seriously."
A resposta levanta, porém, uma contradição direta com o que documentamos. Segundo o Scribd, o problema seria de "postagem não autorizada de informações pessoais" — mas em todos os casos que identificamos, o upload foi feito pelo próprio titular dos dados. A política da empresa não parece contemplar esse cenário específico.
Além disso, a afirmação de que a plataforma usa "ferramentas humanas e automatizadas" para moderar conteúdo é diretamente contradita pelo print "Dados do documento": o sistema de IA do Scribd identificou e resumiu o conteúdo sensível de conversas privadas — e ainda assim manteve os documentos publicados e disponíveis para download.
Por fim, a solução proposta pela empresa — que cada vítima envie um email individualmente para privacy@scribd.com — é inadequada à escala do problema. Estamos falando de potencialmente dezenas de milhares de documentos em múltiplos idiomas.
O Algoritmo e a Responsabilidade das Plataformas
Sob a lente da Lei Geral de Proteção de Dados (LGPD), o que ocorre no Scribd e no Google transcende a simples "falta de atenção" do usuário.
A pergunta que este caso coloca é direta: por que uma plataforma de alcance global não aplica um filtro básico para identificar uploads de arquivos com a formatação característica de logs de chat do WhatsApp — que inclui um cabeçalho padronizado, sequências de timestamps e o aviso de criptografia de ponta a ponta? Não estamos falando de IA sofisticada; uma expressão regular simples seria suficiente para interceptar esses arquivos antes da publicação.
O Google, por sua vez, falha duplamente: ao não identificar o padrão de anomalia representado por milhares de arquivos de log sendo indexados, e ao servir essas informações na primeira página de resultados, amplificando o dano.
O debate sobre até que ponto plataformas digitais podem ser responsabilizadas por conteúdos publicados pelos próprios usuários é central neste caso — especialmente quando há evidências de que os sistemas automatizados das plataformas identificaram o problema e não agiram.
O Que Fazer Se Você Foi Afetado
Se você suspeita ter feito upload de uma conversa de WhatsApp no Scribd, ou encontrou dados seus expostos na plataforma, você pode:
- Buscar seu nome ou número de telefone diretamente no Scribd e no Google
- Solicitar a remoção do documento via formulário de denúncia do Scribd ou pelo email
privacy@scribd.com - Solicitar a desindexação do link diretamente ao Google pela ferramenta de remoção de conteúdo
Esta reportagem será atualizada conforme recebermos posicionamentos oficiais das empresas notificadas. Continuamos apurando aspectos adicionais deste caso.
Gostou da análise? Compartilhe.
Por: Crislei Oliveira.